
Inicio una serie de publicaciones que decidí llamar dIAs, donde explico el uso de herramientas de Machine Learning e Inteligencia Artificial, para probar alguna idea, impulsar o desecharla lo más rápido posible. Hoy toca clasificar imágenes, y en el proceso mostrar el aprendizaje supervisado
Conceptos
En el contexto del Machine Learning, clasificar una imagen es predecir la etiqueta que tendría, mientras que detectar objetos es predecir varias etiquetas a distintas formas de objetos reconocibles en una imagen
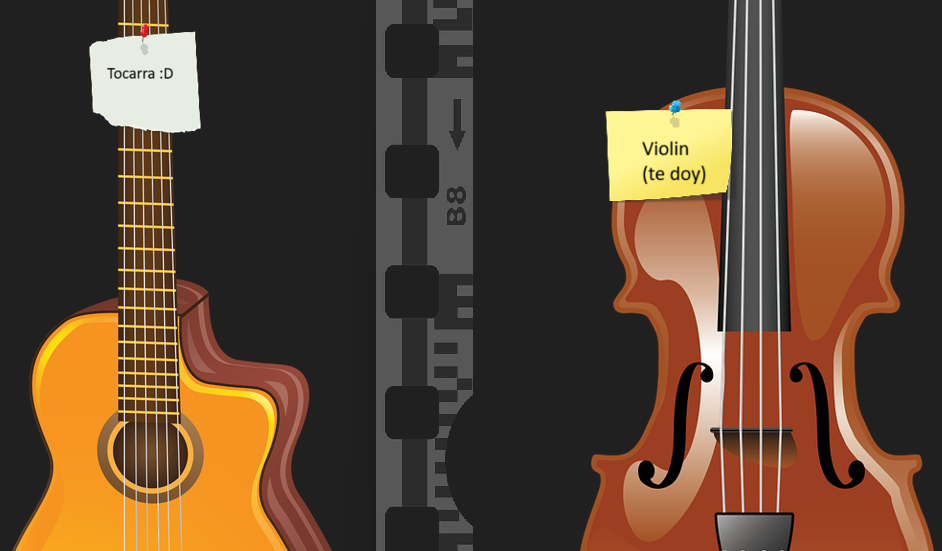
En el ejemplo anterior se aplican etiquetas según lo que se observe, uno como humano aprende en su vida que las guitarras tienen cierta forma, número de cuerdas, dimensiones, en tanto un violín tiene sus propias características; con base a ello determinar qué cosa es cada cuál. Este conocimiento se puede enseñar a las máquinas mediante aprendizaje supervisado.
En el aprendizaje supervisado, generalmente se contemplan las siguientes fases:
- Datos: Es la recolección de datos y su almacenaje, formato, normalización, limpieza. Es la materia prima del aprendizaje, así que trata de no meter porquerías 😀
- Entrenamiento: Es iterar un algoritmo partiendo de un modelo y utilizando tus datos. En cada ciclo se suelen aplicar métricas para determinar si parar o continuar a la siguiente iteración, o también el proceso puede detenerse transcurrido un tiempo de entrenamiento preestablecido. El resultado de esta fase es un modelo entrenado, que puede responder con un número, una etiqueta o una serie de valores
- Evaluación: Aquí pruebas tu modelo con datos que no se usaron en el entrenamiento, y su respuesta debe ser calificada utilizando métricas; para comprobar si está haciendo las cosas como esperamos o no. No hay puntuaciones perfectas para los modelos, siempre hay un grado de error, sé consciente de ello y determina qué tolerancia puedes aceptar; ajusta las métricas, la calidad de tus datos o bien utiliza otro modelo.
- Implementación: Ahora resta disponibilizar tu modelo entrenado algún aplicativo o proceso
Descuida, más adelante vamos a poner en práctica los pasos anteriores.
Extra -> Repositorio: Haz que cada ciclo de procesamiento de CPU o GPU valgan la pena, pon públicos tus modelos entrenados a tu organización. Esto es como armar una tienda virtual de tus modelos entrenados para que alguien más sólo los implemente.
El entorno Local
Es una ventaja tener herramientas de Machine Learning que puedas ejecutar en tu propio equipo de cómputo, y probar alguna idea, experimentar sin preocuparte mucho por configurar un entorno, además de no requerir pagar cargas de trabajo (workloads) en tu etapa de prueba de concepto.
En este post usamos la herramienta ML.Net Model Builder, es una extensión para el famoso IDE Visual Studio, la cual tiene una interfaz visual que te ayudará a entrenar y usar tus modelos de Machine Learning de forma local y gratuita, no necesitas saber programar para poder utilizarla.
Para no detenernos en la instalación, basta con que revises la información en este tutorial de descarga e instalación.
Clasificar Imágenes con Visual Studio
Después de haber realizado la instalación de Visual Studio y de ML .Net Model Builder, inicia Visual Studio y crea un nuevo proyecto
Selecciona una plantilla Aplicación de Consola en C#, esto nos facilitará crear una base del proyecto que no requiera tantos paquetes y librerías; descuida, no escribirás una sola línea de código
Ahora asigna el nombre de tu proyecto y la ubicación del mismo. La casilla para colocar la solución y el proyecto en el mismo directorio es para no crear una carpeta adicional para anidar los archivos del proyecto. Lo dejo marcado porque no trabajaré con tantos proyectos en una solución
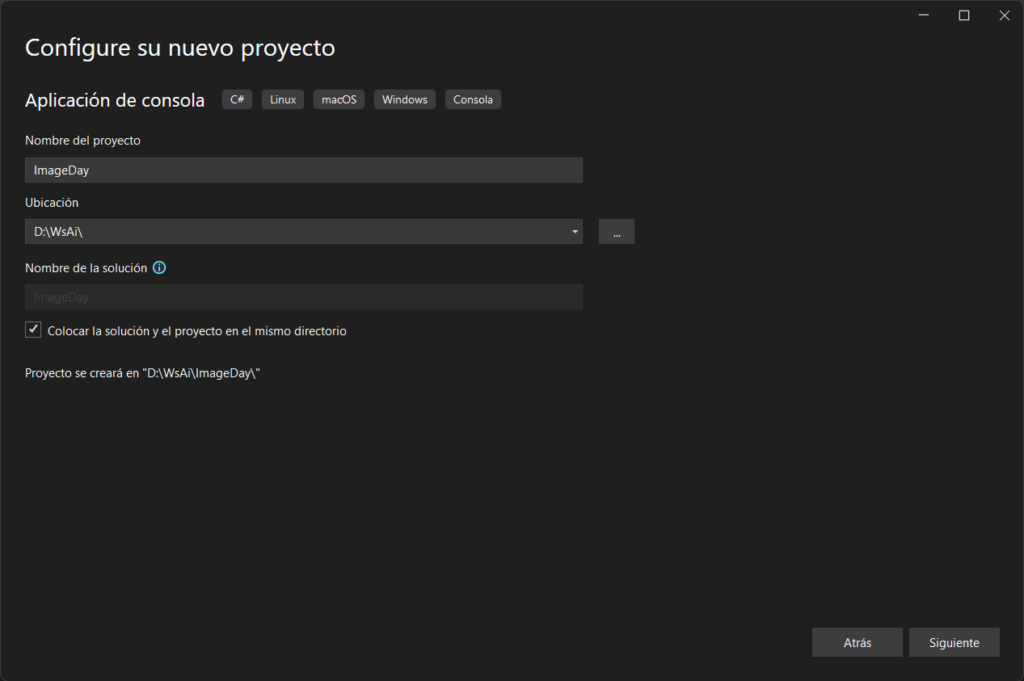
Selecciona el framework más actual; debido a que estamos creando una aplicación de consola con C# y trabajamos con la tecnología .Net de Microsoft, las librerías a utilizar serán del framework .Net
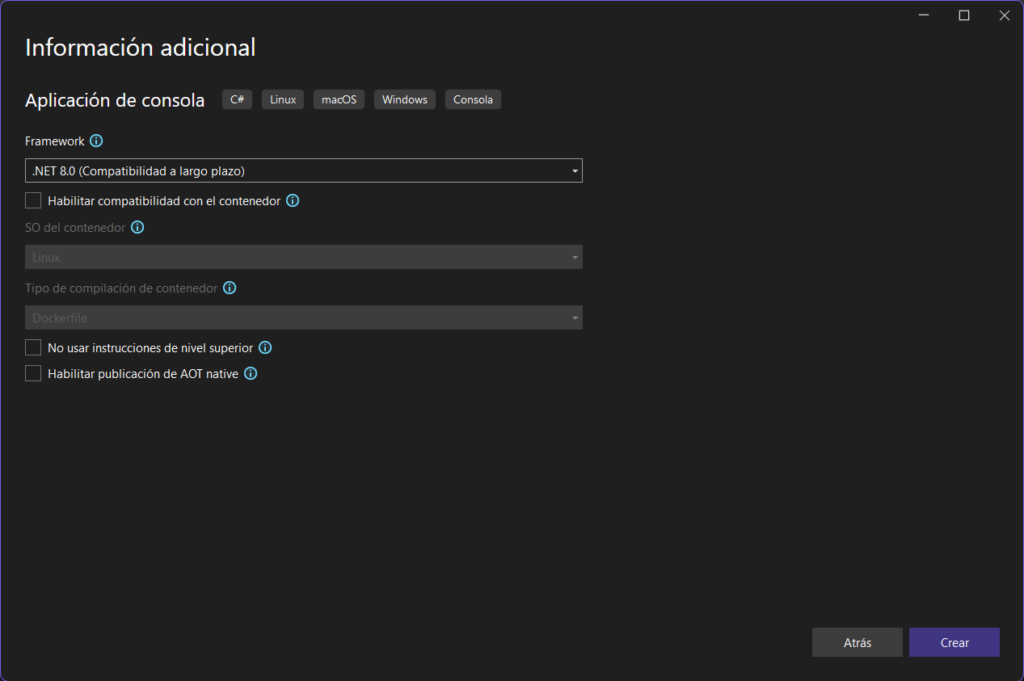
El paso anterior generará de forma automática toda la base del proyecto de consola, y una vez terminado ahora haciendo clic secundario sobre el nombre del proyecto, vamos a agregar un Modelo de Machine Learning, dicha opción estará disponible si has instalado ML .Net Model Builder
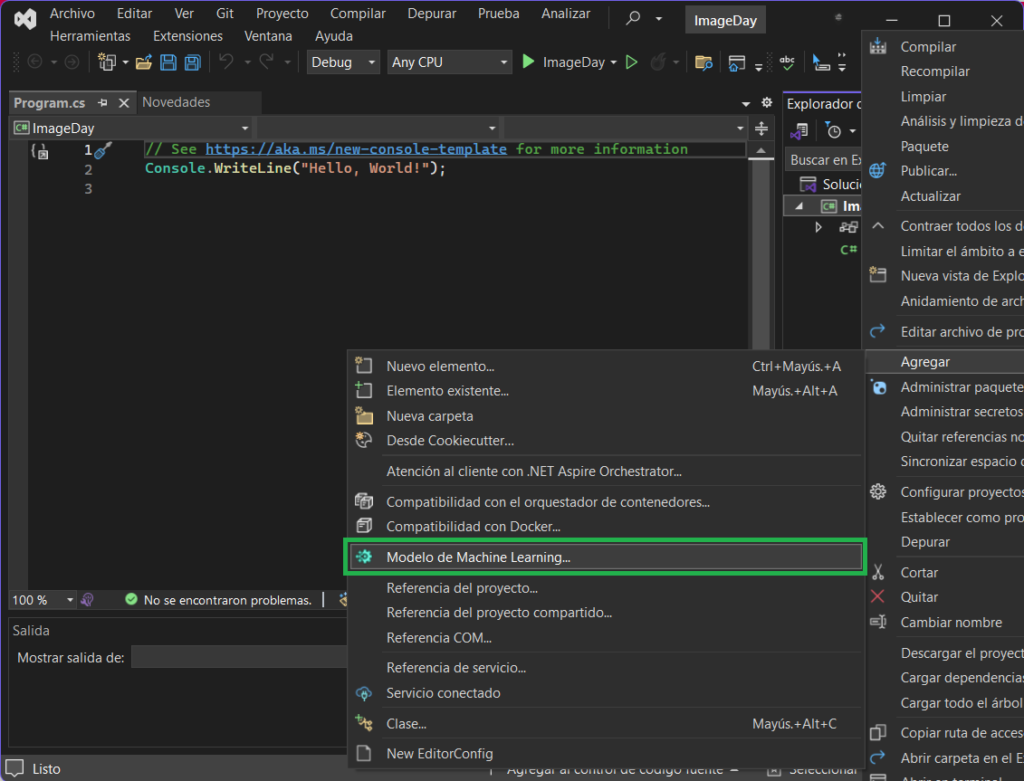
Selecciona la plantilla Machine Learning Model de entre toda la lista de plantillas disponibles, si no la encuentras utiliza la opción de búsqueda de la misma pantalla; luego clic en Agregar
Se abrirá una pestaña en tu entorno de trabajo; hay varias opciones que podrás explorar por tu cuenta más tarde
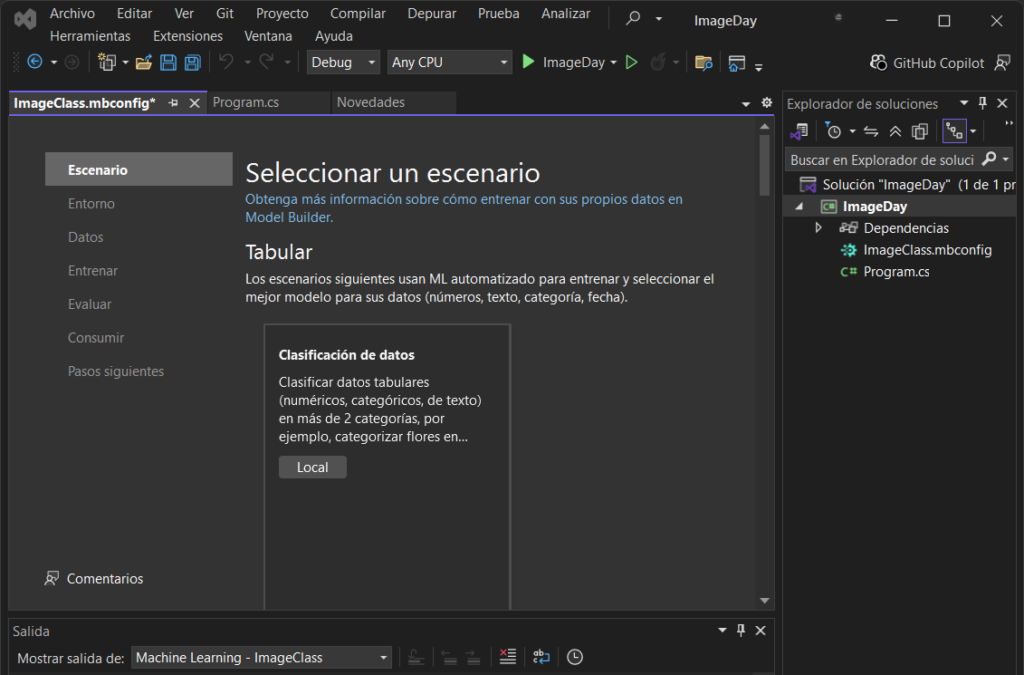
Selecciona el escenario Clasificación de la imagen
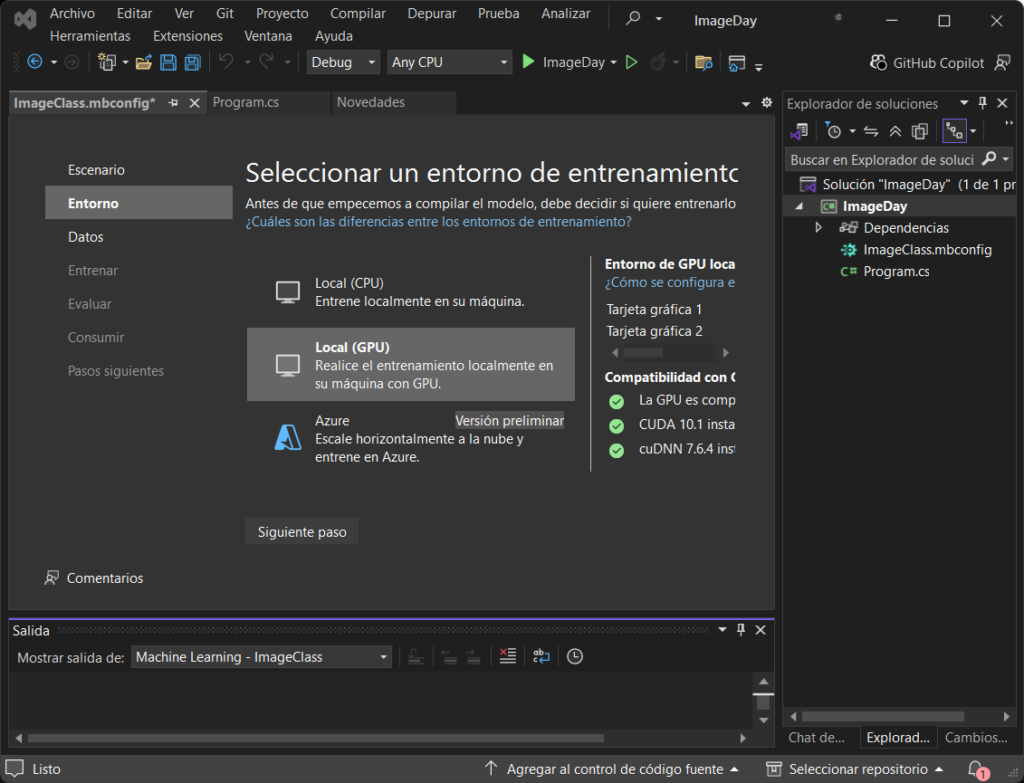
Después de seleccionar tu escenario, es hora de elegir si vas a utilizar tu CPU, GPU, o una carga de trabajo en la nube de Azure para realizar los entrenamientos de tu modelo. Si tu equipo cuenta con GPU, debes realizar una instalación adicional, pero también debes validar que sea compatible con CUDA; si no es el caso, podrás utilizar la opción CPU, no olvides dar clic en el botón siguiente
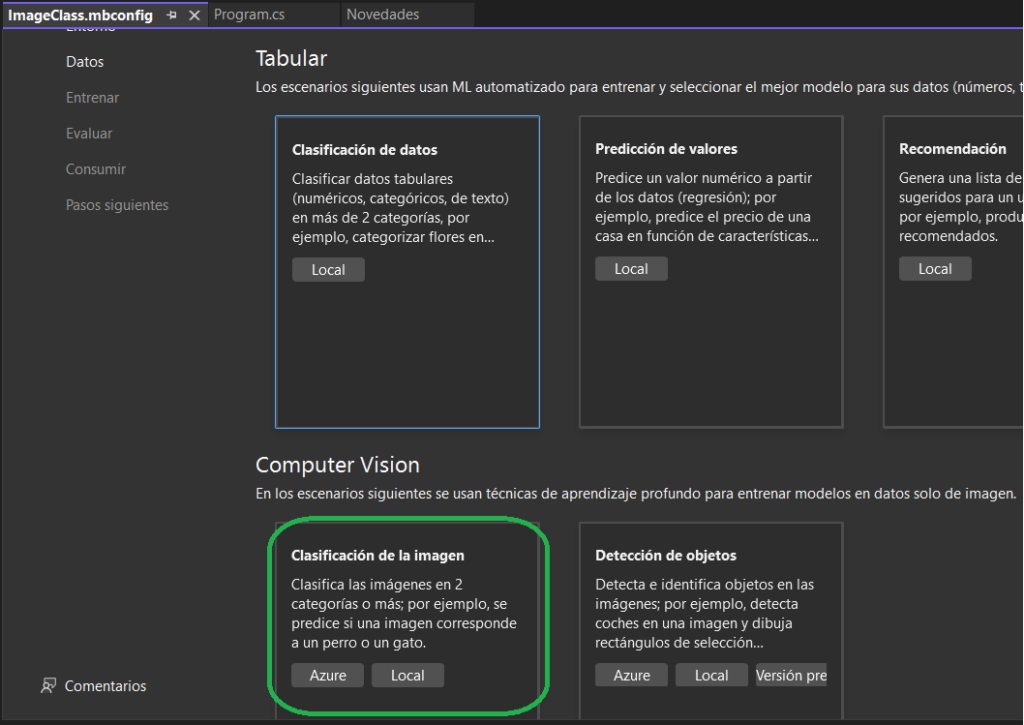
Caso de uso
Como ejemplo, el objetivo es entrenar un modelo que trate de distinguir si una imagen es un control de XBox o uno de PSOne. Podrás tomar como base este caso y los pasos para tu objetivo propio.
Datos y Modelo
Ahora, necesitas datos para entrenar el modelo. Entonces acorde a mi ejemplo necesito imágenes de controles de XBox y PSOne. En tu caso, trata de que en las imágenes sólo aparezca el objeto o cosa a enseñarle a la máquina, si se presenta en un fondo blanco ayuda; además de que lo muestre desde ángulos distintos.
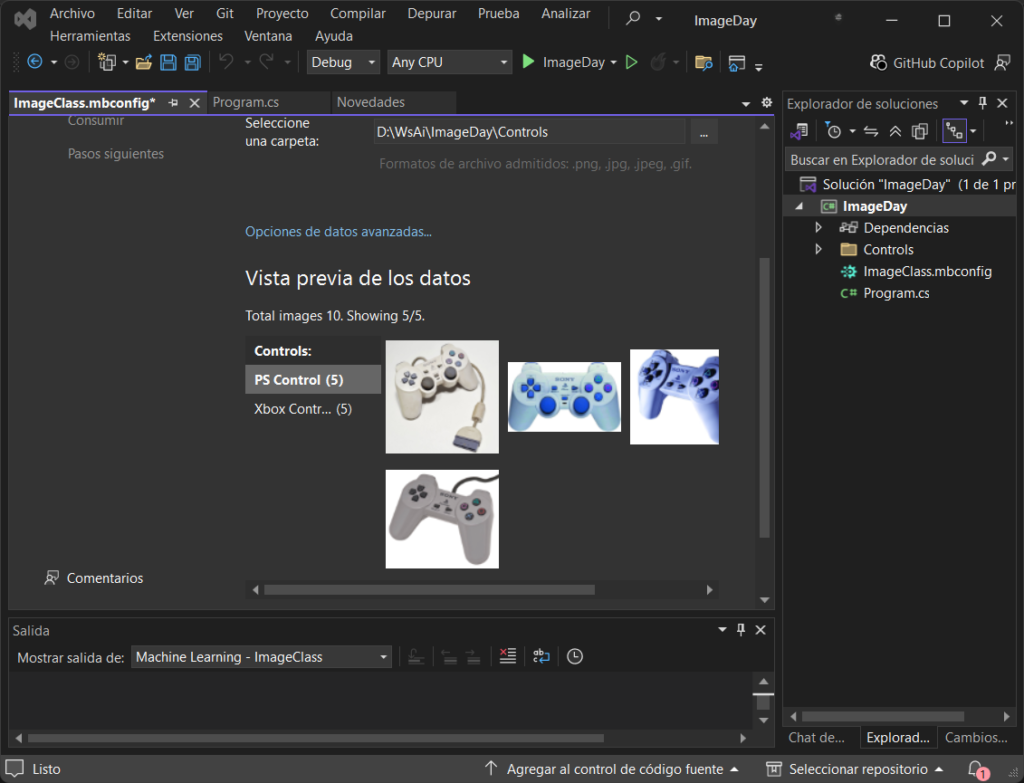
Organiza y agrupa tus imágenes en carpetas diferentes, el nombre que les asignes se utilizará como valor de etiqueta
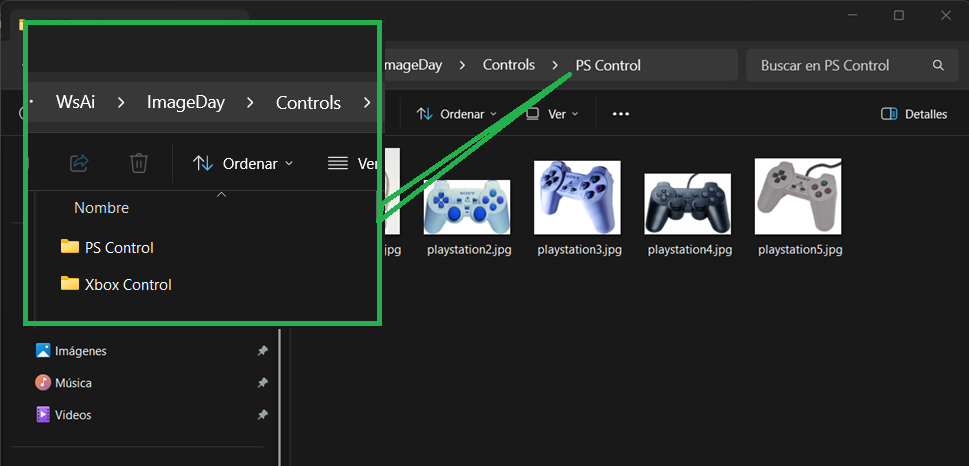
¿Y la elección del modelo? la herramienta elegirá por ti el modelo que haya tenido el mejor desempeño durante la fase de entrenamiento, basado en métricas; aunque tiene opciones avanzadas, recuerda que utilizar este tipo de herramientas nos ayuda a probar rápido nuestras ideas, hagámoslo simple durante nuestros primeros pasos ¿De acuerdo?
Entrenamiento
Ahora toca dar clic en Iniciar el entrenamiento
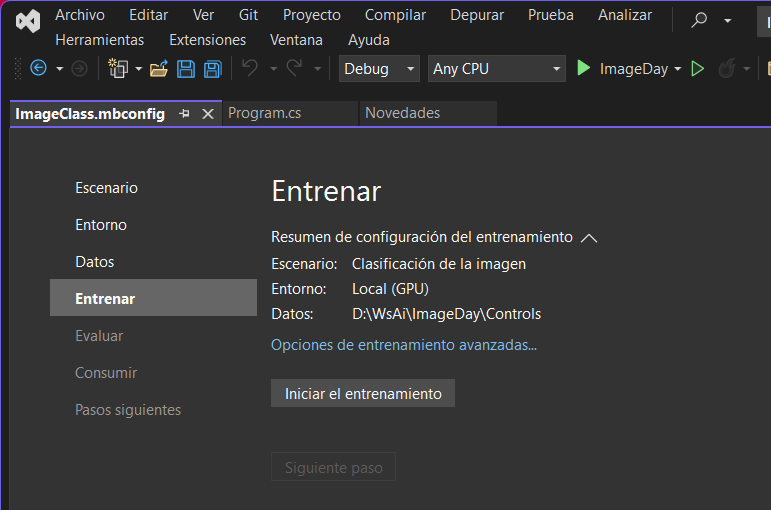
El proceso de entrenamiento llevará un tiempo, depende del número de imágenes que tenga qué procesar, por lo que hay qué esperar y estar pendiente de los mensajes que el sistema arroje
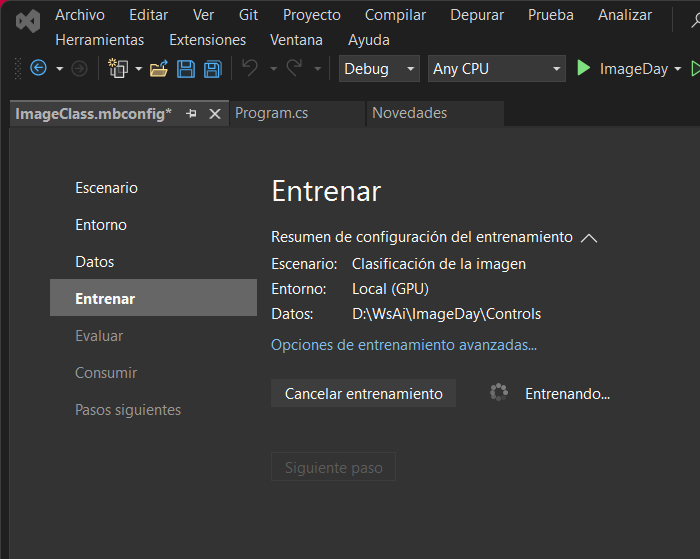
Cuando el entrenamiento termine, el botón del Siguiente paso se habilita
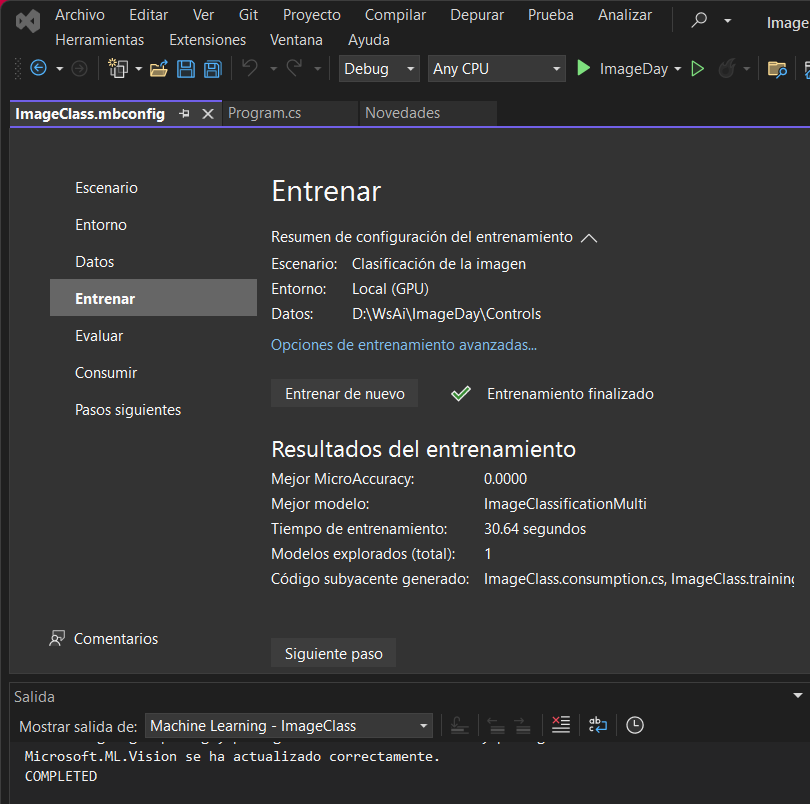
Evaluación
Resta evaluar el modelo entrenado, para comprobar si está funcionando como lo esperado. Para este paso se te pedirá cargar una imagen de prueba, es recomendable utilizar imágenes que no fueron utilizadas en el proceso de entrenamiento, y la evaluación se activará enseguida; al final se muestra una columna que dice Resultados, donde estará expresado el porcentaje de probabilidad de cada etiqueta que el modelo dice hay en la imagen. Cada texto de etiqueta, ML Builder lo extrajo del nombre de las carpetas que indicaste en el paso de Datos
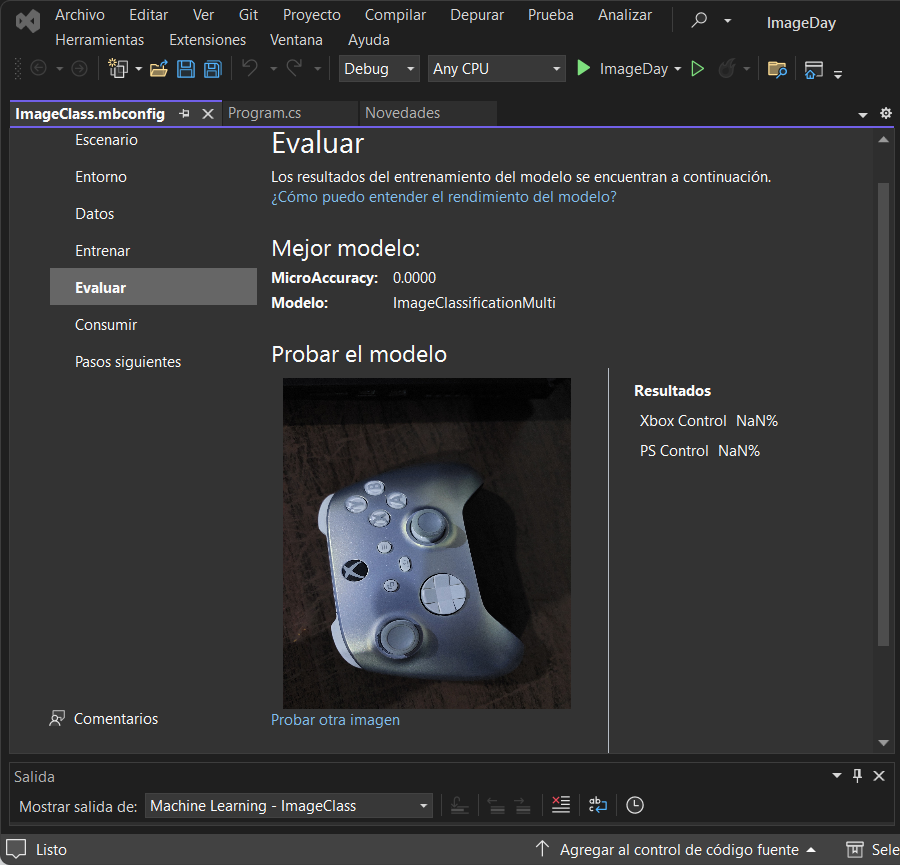
Como puedes ver, la primera y segunda imagen de prueba que cargué arrojaron como resultado «NaN» en cada etiqueta, estas letras significan “Not A Number”; al parecer el modelo no está prediciendo como se espera y es cuando hay qué probar aumentando la cantidad de datos con las qué entrenar, ya que en mi caso comencé con sólo 5 imágenes
Reentrenamiento
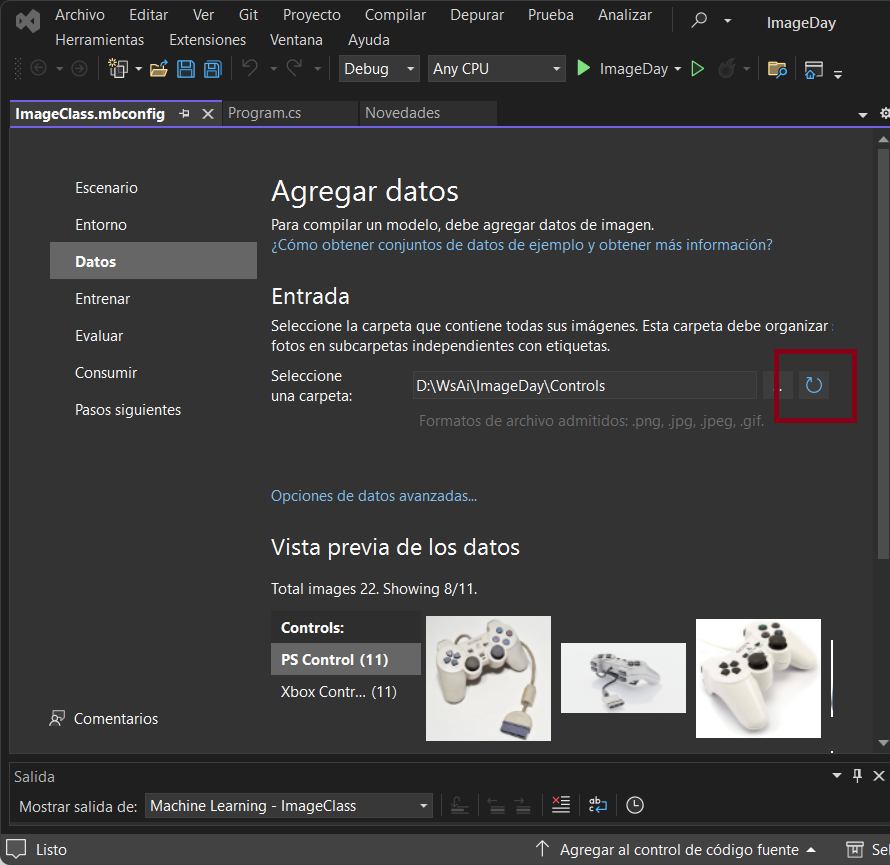
Regresa los pasos para incluir más datos de prueba, lo que se hace es agregar más imágenes en las carpetas que seleccionaste, luego en la fase Datos dar clic en el botón para actualizar
Avanza a la fase de evaluación otra vez, ahora verás un botón que dice Entrenar de nuevo, porque previamente ya habías entrenado un modelo
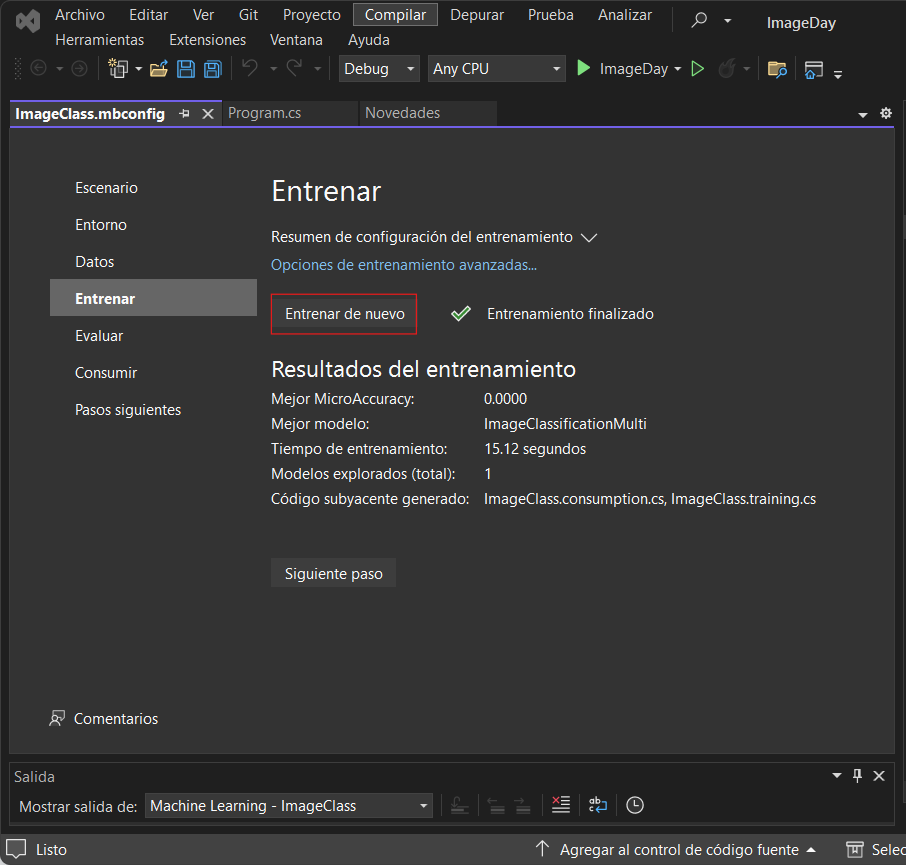
Espera a que el entrenamiento finalice y da clic en Siguiente paso
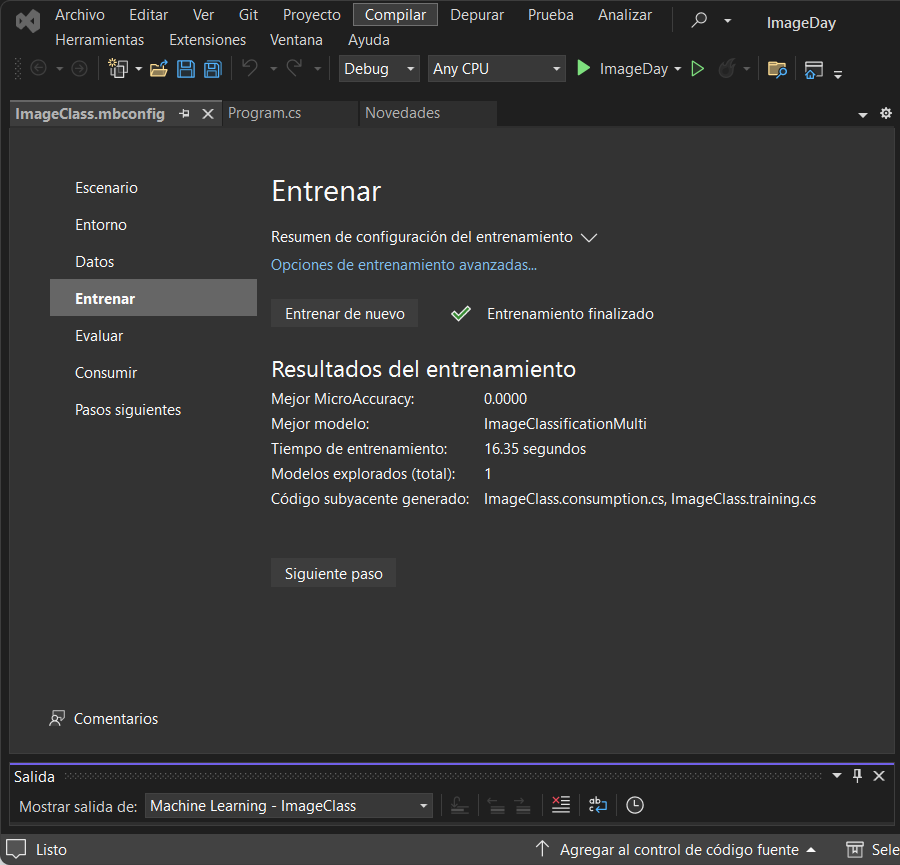
Realiza nuevamente la prueba y verifica los resultados
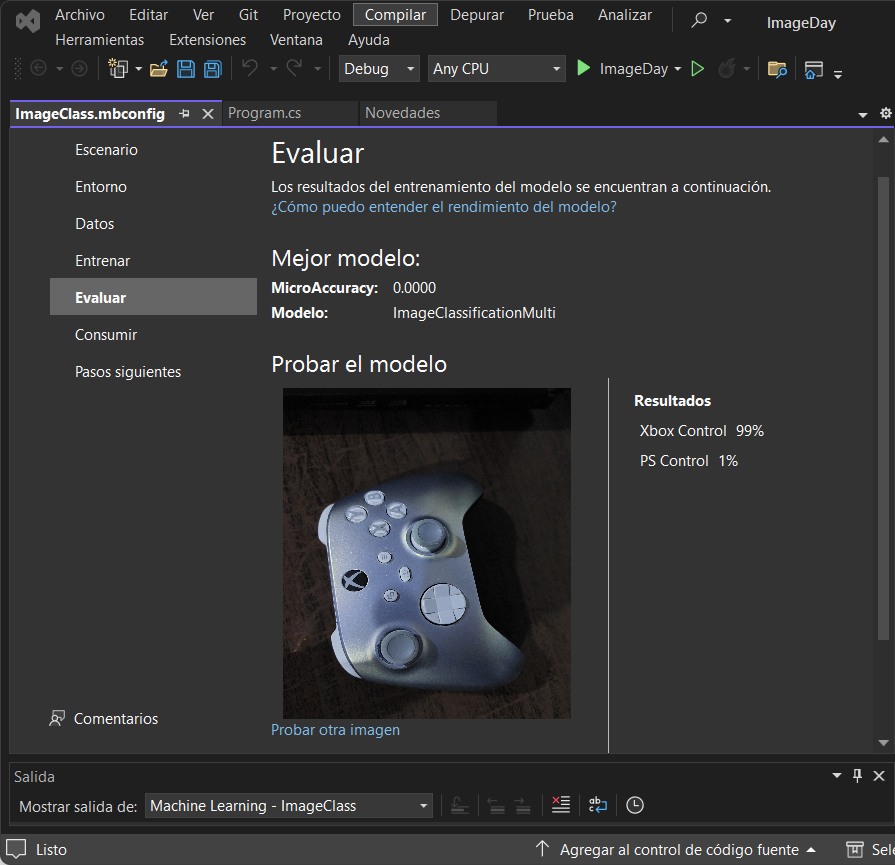
Como puedes ver, los resultados tienen orden descendente, además se observa que dependiendo la imagen el valor del porcentaje varía. Visualmente puedo decir que mi modelo entrenado está funcionando como se espera, al ver valor de porcentaje alto en Xbox Control cuando cargo la imagen de un control de Xbox y porcentaje alto en etiqueta PS Control cuando pruebo el modelo con una imagen de Psone
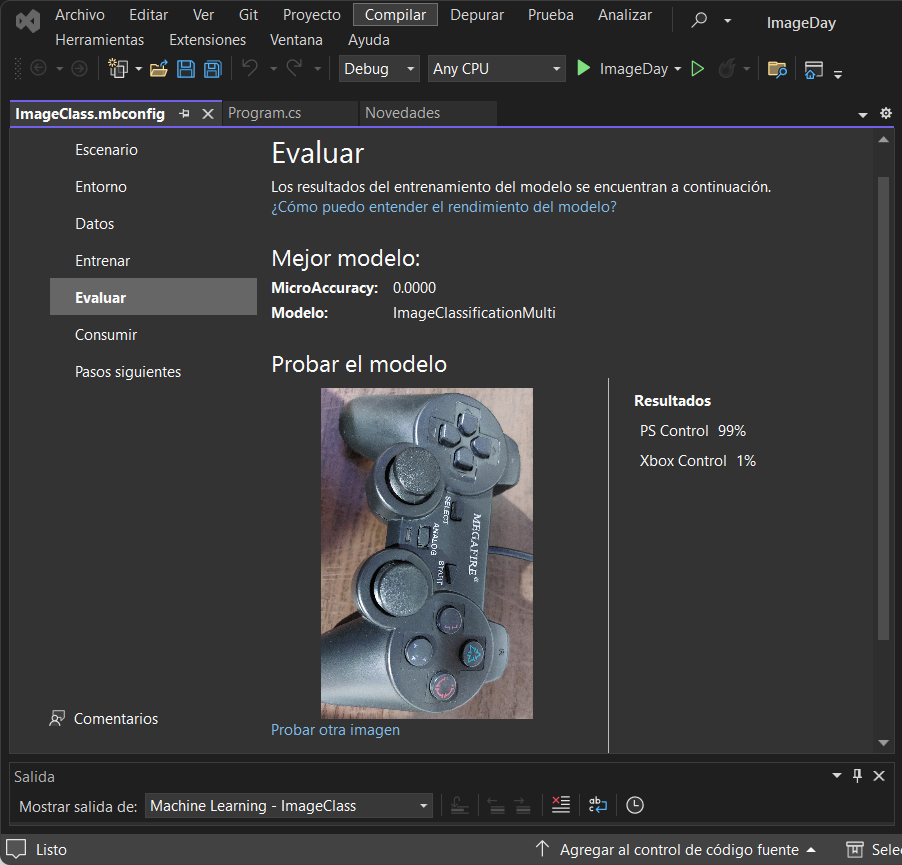
Tal vez te preguntes ¿Por qué una etiqueta tiene un porcentaje mayor y otra menor? ¿Significa que hay algo de control de Xbox en el control de Psone? ¿Estoy ante una paradoja increíble? 😱
Es importante tener presente que una máquina calcula y regresa resultados probabilísticos, por lo que habrá valores para todas las etiquetas; aunque sea mínimo, la herramienta así lo hará . Entonces es imprescindible contar con métricas y métodos que nos ayuden a establecer el porcentaje o tolerancia de error que podemos aceptar para decidir si nuestro modelo está funcionando como se espera. Por lo pronto, puedes seguir experimentando, sin un criterio riguroso, sin embargo cuando tu solución planteada se vaya a utilizar en algo serio, sí o sí es requerido meter controles para que tu sistema tenga un nivel de confianza aceptable. Por eso se llama aprendizaje supervisado 😃🧐
Eso, alócate y prueba otra cosa 🤪
¿Y si probamos el modelo con una imagen con algo diferente? Se puede hacer, la siguiente prueba utiliza una imagen de control de otro dispositivo y estos fueron resultados:
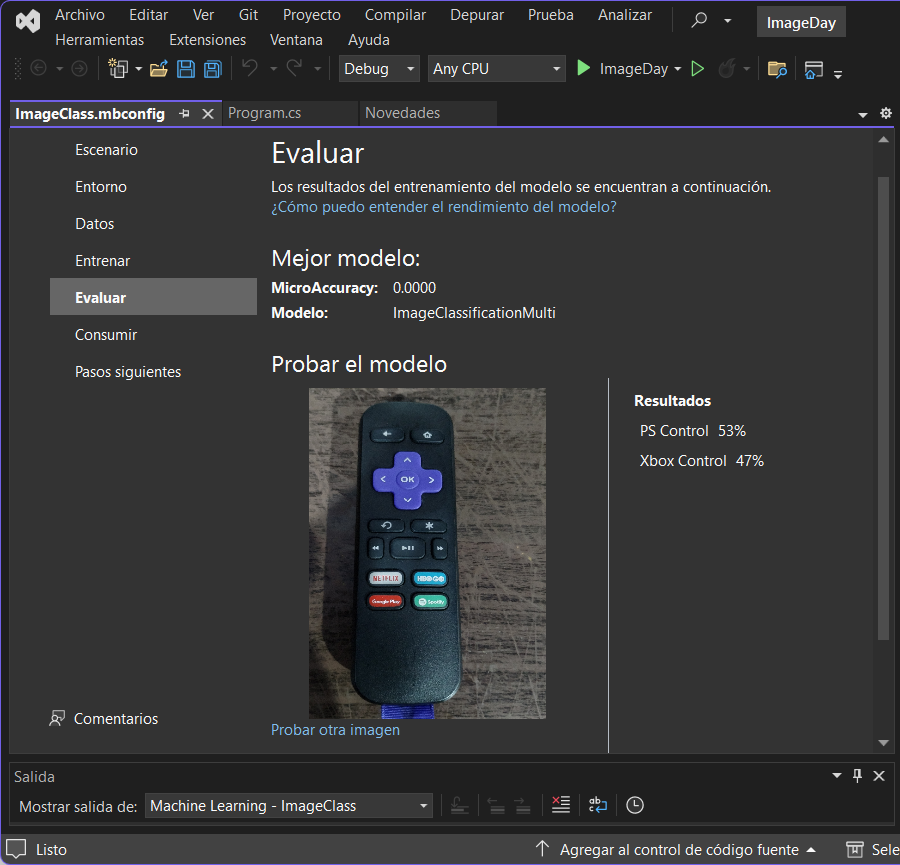
La herramienta arroja PS Control 53% y Xbox Control 47%, esto no quiere decir que la imagen tiene un poco de control de Xbox y otro poco de control de Playstation, así no funciona 😅 lo que significa es que para cada etiqueta, el modelo regresó un cálculo según la imagen dada; es evidente que los porcentajes no son muy altos y tampoco tienen una brecha muy amplia entre ellos, por lo que se puede interpretar que en la imagen en cuestión no hay alguno de los controles que deseamos predecir.
Hipotéticamente, si hicieras un sistema que clasifique imágenes entre dos, tres, o ene clasificaciones, pero que descarte o elimine las que no entran en ninguna, podrías hacer el descarte basado en si al evaluar notas que ninguna de sus etiquetas sobrepasa algún umbral que establezcas (como un 70% o más)
Crear Aplicación de Prueba
Como mencioné previamente, no necesitas escribir una línea de código utilizando esta herramienta, así que después de entrenar y probar tu modelo, y estar satisfecho con los resultados, la herramienta te da la opción de agregar un proyecto de Consola o API Web.
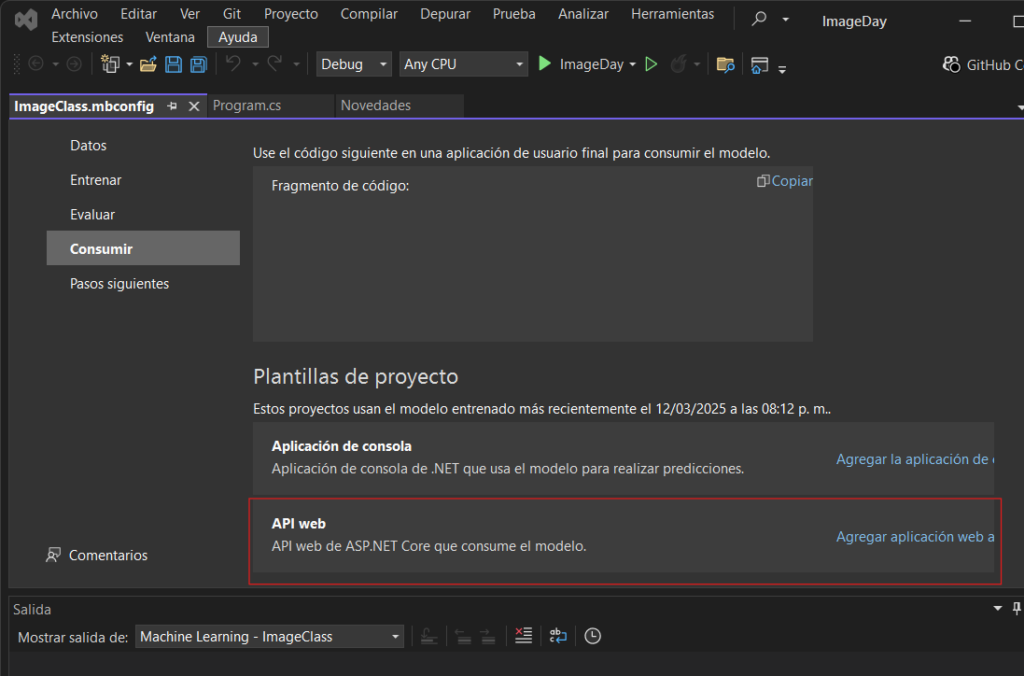
Elegimos la opción API Web y nos pedirá un nombre para el proyecto
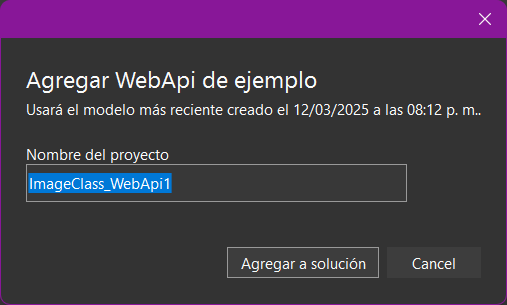
Automáticamente la herramienta nos genera un proyecto de tipo API Web, con todo el código necesario para probar nuestro modelo y exponerlo mediante servicios Web que podrías montar en un servidor y consumir desde internet
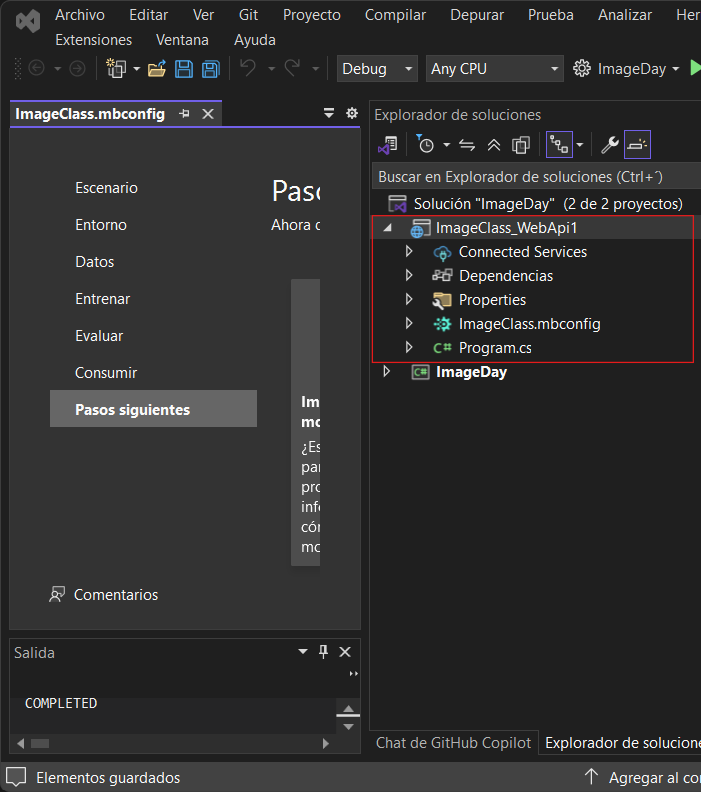
Para probarlo, se da clic secundario sobre el proyecto nuevo que la herramienta generó y dice algo como WebAPI; luego en el menú contextual clic en Establecer como proyecto de inicio, tras esto notarás que el texto con el nombre del proyecto ahora se ve con la fuente en negritas
Ahora al pulsar la tecla F5, el IDE Visual Studio levantará el aplicativo configurado como proyecto de inicio; o bien ejecuta tu aplicativo desde el menú Depurar (debug)
Podrás ver cómo se abre el navegador en una URL, esta es una dirección que apunta a tu máquina y que a su vez pertenece al aplicativo que está ejecutándose; varía entre aplicativos que hayas realizado previamente en tu IDE, y entre IDEs de otros desarrolladores.
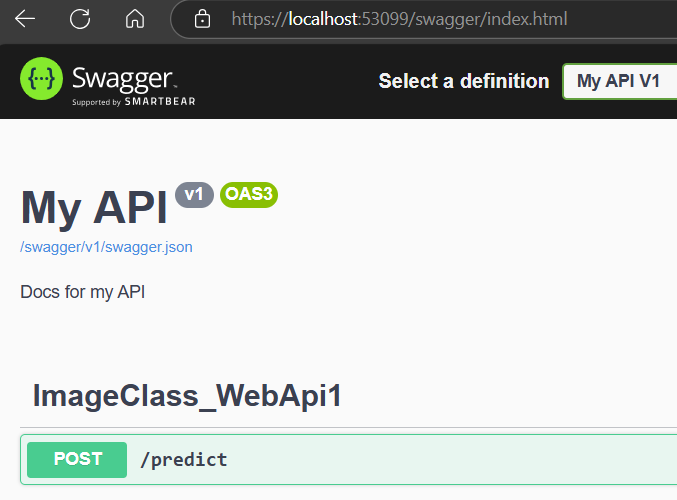
Como la herramienta es muy completa, incluye otra herramienta llamada Swagger, te ayudará a probar tus servicios dentro del mismo navegador, sólo añade la ruta modificando la URL. En mi caso la ruta lanzada por mi IDE Visual Studio fue https://localhost:53099/, por lo tanto la nueva ruta queda como https://localhost:53099/swagger Observa que sólo estoy añadiendo una palabra al final respecto a la primera URL; al navegar en la nueva dirección se verá la siguiente pantalla
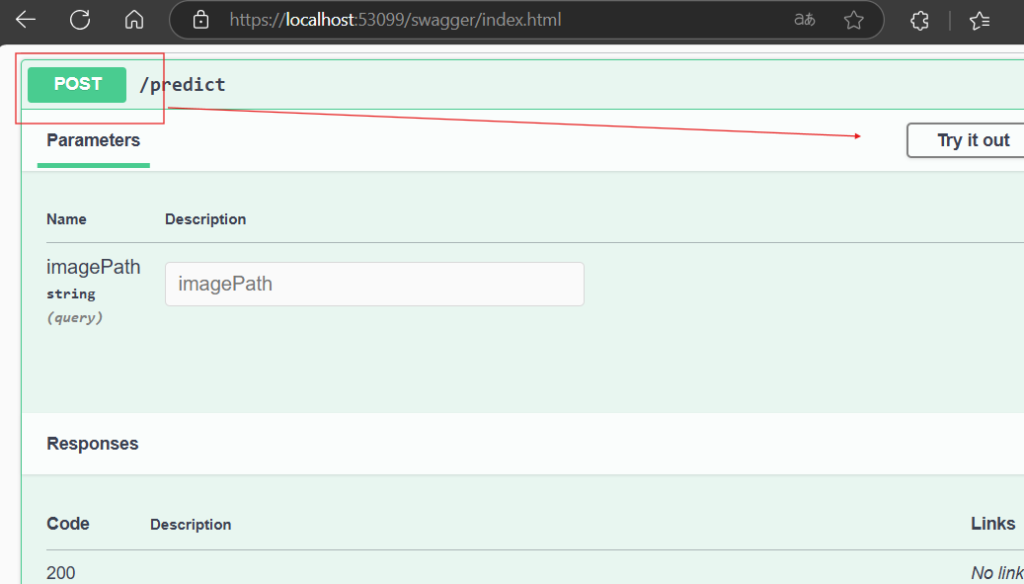
Ahora le daremos click donde dice POST y en Try it out, tras hacer esto, notarás que la caja de texto se habilita para que podamos introducir texto
Consumir mi modelo entrenado
Hasta este paso lo que hemos realizado es poner en marcha nuestra aplicación, misma que expone mediante un servicio nuestro modelo entrenado.
En palabras burdas, estamos dándole vida a nuestro modelo entrenado, para que podamos interactuar con él, en este caso mediante una URL que bien podría accederse desde internet. En esta interacción, el programa nos pide la ruta de la imagen que queremos clasificar, y después se debe dar clic en el botón Execute para enviarle esa imagen a nuestro modelo
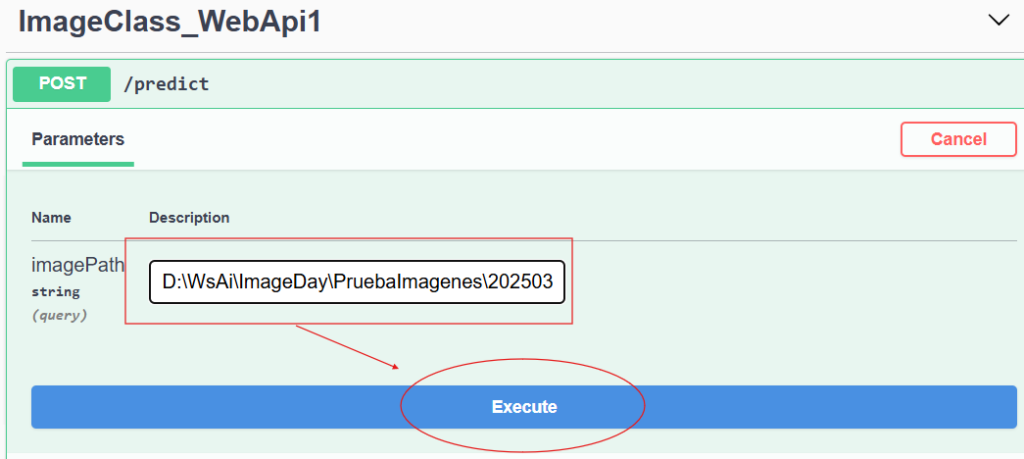
Si todo va bien, nuestra aplicación nos habrá lanzado una respuesta con un código numérico que debe ser 200; en caso contrario, podrás recibir un código que comience con 5 o con 4. Pero aunque el código 200 nos dice que el proceso se ejecutó exitosamente, no da una respuesta que buscamos: saber qué clasificación le dio a la imagen de la ruta que indicamos, así que hay que utilizar el scroll para buscar el resultado.
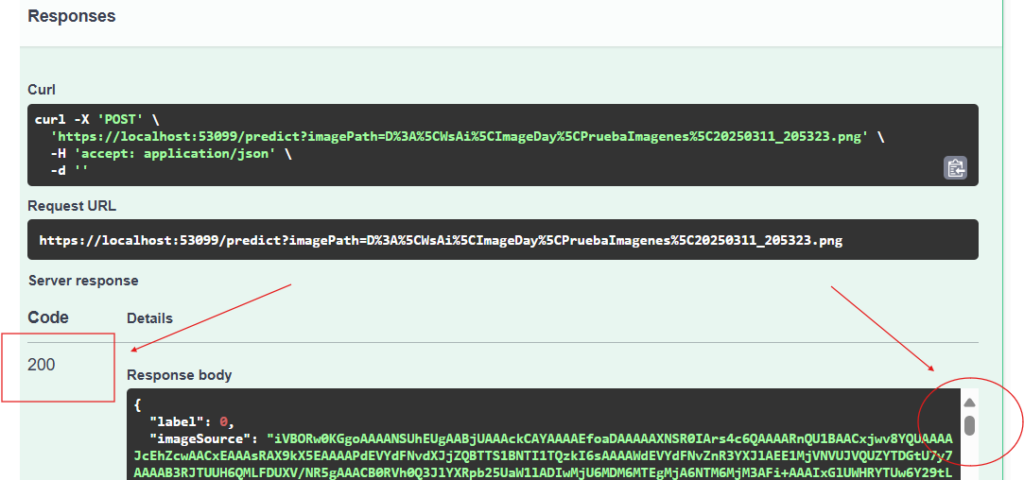
Debemos buscar dos textos en la respuesta:
- predictedLabel: delante de este texto, encontraremos la etiqueta que pudo predecir nuestra aplicación, y que tuvo el valor de probabilidad más alto respecto a otras etiquetas (o score).
- score: aquí encontrarás varias cifras decimales, dentro de corchetes y separadas por comas, los valores van del 0 al 1; entre más cercano al 1 esté una cifra, significa que hay una alta probabilidad de su predicción, y más lejos del 1, representa una baja probabilidad. La cifra más cercana al 1 será la de la etiqueta en predictedLabel
En palabras más humanas, lo que nuestra aplicación quiso decirnos es que la imagen que le proporcioné, predice que hay una probabilidad de que se trate de un control de XBox.
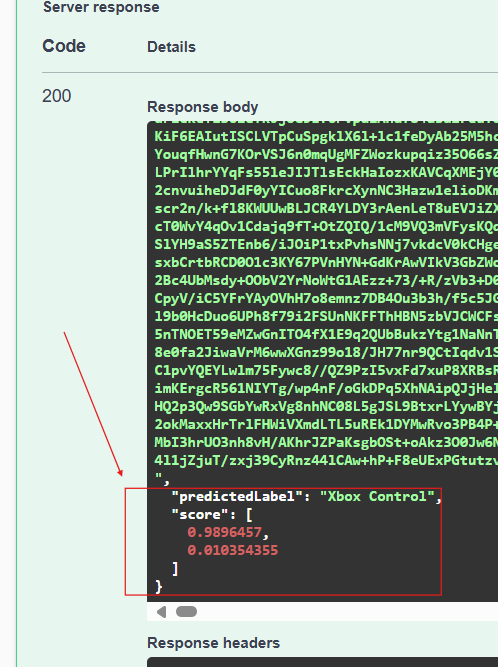
Se puede realizar prueba con otra imagen; en mi ejemplo, ahora indico la ruta de una imagen de control de Roku y luego clic en Execute. Lo que se puede apreciar es que predictedLabel tiene una etiqueta, al menos una de las dos (PS Control), pero luego al revisar los valores de score, y cerrandolo a dos decimales, tengo 0.47 y 0.52; para efectos prácticos y visualizar mejor, puede multiplicar por 100 para tener un 47 y 52 que sería el porcentaje de probabilidad en predicción de la etiqueta que hizo el modelo
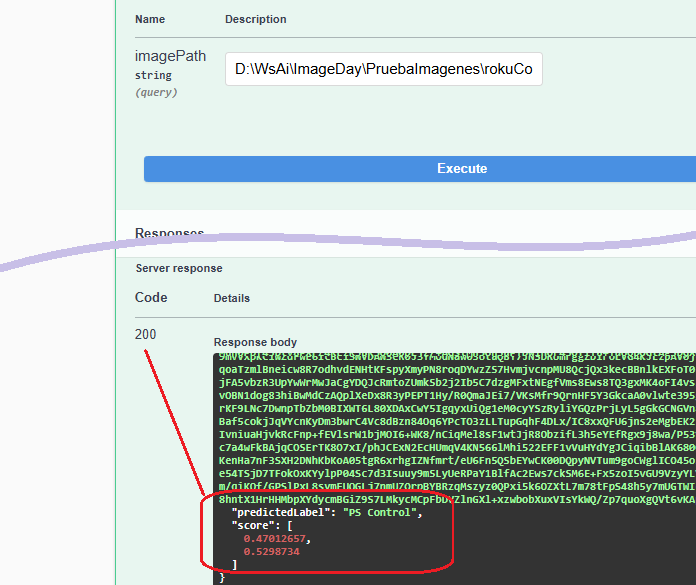
Como comenté anteriormente, la etiqueta en predictedLabel es la que mayor probabilidad, calificación (o score) tuvo, por lo que en mi ejemplo obtuve un 0.52 (52%) este valor en realidad no es que sea muy cercano al 1 (o bien un 100%), además, no hay una gran diferencia respecto a la otra cifra de 0.47 (47%). A pesar de que la respuesta de la aplicación tuvo un código 200, los resultados sobre la etiqueta y las cifras, no tienen valores que ayuden a clasificar con un buen nivel de confianza, y esto pasa porque utilicé una imagen que no tiene qué ver con un control de XBox o de Playstation, pues el modelo no fue entrenado para reconocer otros tipos de controles; así que el modelo está respondiendo como espero.
😸👍
日曜日
Este día mostramos el proceso de aprendizaje supervisado mediante clasificación de imágenes. Los datos (imágenes) son un ingrediente muy importante, por lo que deben ser confiables. Finalmente en la elección de un modelo hay facilidades, sin mucha intervención del usuario, al decidir por un caso de uso habrá un listado de modelos probados y especializados para ciertos propósitos, como clasificar imágenes, detectar objetos, predecir tendencias, reconocer patrones.
それではまた明日
Entradas relacionadas



Ingeniero en Comunicaciones y Electrónica, dedicado al desarrollo de software y apoyo a la comunidad en temas de tecnología, especialmente en temas de IA. En lo personal disfruto practicar guitarra, viendo algún buen anime.

